

Using Parametric Sentiment Analysis Of Russian Telegram To Identify and Understand Human Rights Violations In Occupied Areas Of Ukraine
By Mollie Upchurch and Justin Young
Abstract
AI-based sentiment analysis has recently proven useful through the mining of large amounts of text. These texts can be drawn from various sources, but most valuably can be used to reach conclusions about public opinion, especially regarding current events. As a result, sentiment analysis provides a method for researchers to determine public opinion under authoritarian regimes through the medium of social media. Using social media allows researchers to find a closer approximation of genuine sentiment, as opposed to analysis of state propaganda or other strictly controlled media. This could be especially valuable in regards to Russia’s ongoing war in Ukraine, given the limited reliability of traditional opinion polling in a closed society. However, most sentiment analysis databases are drawn from English language texts, with relatively few based on Russian. This paper examines the existing scholarship on Russian-language sentiment analysis and its effectiveness when conducted based on social media texts, including the complications arising from the differing lexical structures of the language.
Background
Academic research has reached mixed conclusions on the effectiveness of AI sentiment analysis. Sentiment analysis has proven significantly more effective when run on English language datasets than on Russian, since AIs encounter difficulty interpreting meaning when confronted by the complicated grammar structures of Russian. These complications can be partially resolved by machine translation of the source texts. However, machine translation brings with it the problem of potential flawed translations reducing the source fidelity of the data. Despite these drawbacks, analysis of Chat GPT assisted translation often demonstrated higher effectiveness than models relying on untranslated Russian itself, emphasizing the complications posed to sentiment analysis by non-linear languages.
Methods
The Telegram posts for this paper were drawn from a random sample of public channels focused on news in November 2023. The posts were collected through a custom algorithm that scraped the data of the posts for a specific week during that month. The channels were selected through analysis of the most popular Russian channels as measured by subscriber count. We used data two channels with differing political emphasis, one strongly pro-war with a focus on military operations and one focused on entertainment news. Comments were collected from a channel focused on political news with a diverse subscriber base including not only supporters of the government but those who emigrated abroad due to their opposition to the war. These comments were manually collected from a series of posts focusing on news related to the March 2024 terrorist attack on Crocus City Hall in Moscow.
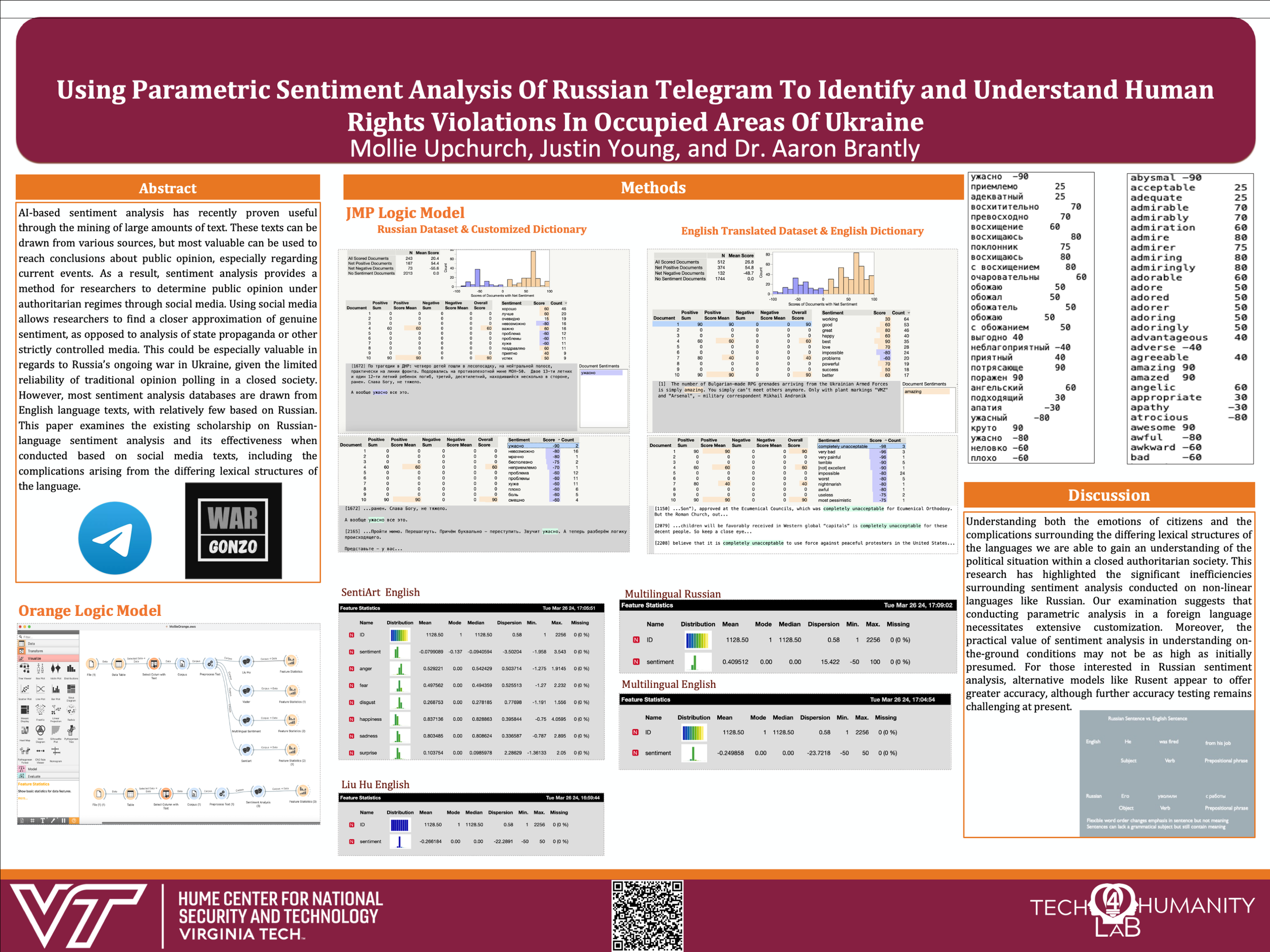
The study aims to determine genuine public opinion regarding the Russian Ukraine war through sentiment analysis of data obtained from the Wargonzo Telegram channel due to Twitter's new regulations limiting data collection. Unlike other social media platforms, Telegram's limited content moderation allows for the gathering of more authentic opinions, especially in contexts with restricted freedom of speech and high propaganda levels. Data preprocessing involved customizing a Russian dictionary for sentiment analysis in the statistical software JMP, which utilizes the Liu Hu sentiment analysis model. However, limitations arose as the model was built for English, leading to inefficiencies and discrepancies between sentiment scores and actual sentiment in the Russian dataset. To address this, the dataset was translated to English, resulting in higher accuracies. Further analysis was conducted using data mining software Orange, which employs various lexicon models, including Liu Hu, Vader, Multilingual, SentiArt, and LiLaH. While Multilingual offered a Russian option, it proved highly inaccurate. The study's methodology underscores the complexities of sentiment analysis in non-linear languages and authoritarian regimes, offering critical insights into public opinion and challenges posed by war, thereby contributing to human rights advocacy.
Structural differences
Russian grammar is strongly distinguished from English grammar in that it includes six cases instead of three, five possible verb conjugations instead of two, and masculine, feminine and neuter grammatical gender. Thanks to the existence of cases and verb conjugations, word order in a Russian sentence can be much more flexible than in an English sentence. For example, while in English the subject must be placed at the front of the sentence, in Russian the subject can be placed anywhere depending on the emphasis that the speaker wishes to communicate. These differences in word order complicate sentiment analysis, especially as one word can have up to six different forms depending on the grammatical case used. Lexically, Russian is strongly distinguished from English due to its origins as an East Slavic language while English is a mix of French, Latin and Germanic words.
As a result of the significant grammar differences between Russian and English, sentiment analysis software fails to distinguish between different cases of words in a sentence. Since traditional software tailored for linear languages cannot detect the meaning of sentences communicated through case endings, this significantly compromises the accuracy and reliability of traditional sentiment analysis, as errors in meaning completely change the data's interpretation. To reduce the amount of error, a specialized dictionary was created that incorporated words whose case does not change, but this in turn created potentially negative biases towards data as many of these words carried a negative implication or included profanity. At the same time, it can be difficult to assign sentiment scores to specific words out of context as the connotation of words can change depending on the context, and sentiment analysis software is unable to detect sarcasm or nuance in texts. Therefore, the effectiveness of sentiment analysis is significantly constrained by the inability of software to adapt to the syntactical patterns of non-linear languages.
Implications
Understanding the emotions of citizens and the complications surrounding the differing lexical structures of these languages, we can understand the political situation within a closed authoritarian society. This research has highlighted the significant inefficiencies surrounding sentiment analysis conducted on non-linear languages like Russian. Our examination suggests that conducting parametric analysis in a foreign language necessitates extensive customization. Moreover, the practical value of sentiment analysis in understanding on-the-ground conditions may not be as high as initially presumed. For those interested in Russian sentiment analysis, alternative models like Rusent appear to offer greater accuracy, although further accuracy testing remains challenging at present.