

By Ryan Mason
Ransomware poses a persistent threat in the cyber landscape. Over the past four years, there have been more than 19,000 recorded ransomware attacks and leaks, with the number of victims increasing daily. The massive number of attacks in such a short timespan highlights the importance of understanding the tactics employed by ransomware groups.
Criminal hacking groups that use ransomware commonly employ a strategy called double extortion. In this approach, hackers not only encrypt and steal companies' data but also threaten to release the stolen data on a dark web blog if the ransom is not paid. These blogs serve as valuable resources for understanding ransomware groups’ motives, targets, and technological capabilities. Posts on these blogs typically include a victim’s name, a description of the victim, and files associated with the leak, which can range from internal documents to blueprints to bodycam footage. Hackers may include anything they deem valuable or incriminating.
Navigating these blogs can be time-consuming and challenging. Utilizing Tor presents difficulties and inconveniences. Tor operates via a network of decentralized nodes or relays around the world. To connect to a Tor site, traffic will be sent through three nodes. Each relay only knows the relay before and after it, resulting in a completely anonymous connection by the time the traffic reaches its destination.[1] The dark web’s architecture makes it challenging to locate any dark web site, let alone a ransomware blog. Extracting information from these blogs is even more arduous. Numerous ransomware groups employ Captcha technology to thwart authorities from shutting them down and researchers who utilize web scraping tools to expedite their data collection process. Manually parsing, downloading, and logging data from the 65 active sites would be too time consuming and slow to yield actionable insights.
RansomLook addresses these challenges. This open source, Clearnet database houses data from over 16,000 attacks, 2,000 leaks and nearly 200 groups, with more added daily. The platform meticulously collects information on some of the most prolific ransomware, including LockBit3, Cl0p, and AlphV. RansomLook has built off existing tools and added new technology to provide a clearer look into a murky landscape.
RansomLook Tech Stack
RansomLook is based on RansomWatch, a live repository developed by Josh Highet. RansomWatch monitors hosts and provides real-time updates on their status. It uses the Requests HTTP library to download HTML documents and Geckodriver and Selenium to display the HTML documents as they would appear on a website.[2][3][4]
After the media has been downloaded, RansomWatch indexes the data using built-in Linux commands such as grep for regular expressions, awk for data manipulation and report generation, and sed for text manipulation in files. This combination of tools provides a robust framework for input and sorting data in the database. However, the RansomWatch repository notes that the script employing these tools lacks reliability and has a limited lifespan due to the potential impact of software updates on the tools’ functionality. The processed data is subsequently outputted to a JSON file, which can be utilized for further analysis. RansomWatch can also be accessed in a GUI format via its website.

RansomWatch Site
RansomLook leverages the strengths of RansomWatch while addressing its shortcomings. Data storage is optimized to reduce CPU strain and enhance data ingestion speeds. Website scraping is multithreaded, accelerating data collection and improving resource allocation. Web scraping has been upgraded from Requests to a combination of BeautifulSoup and Playwright. BeautifulSoup is a Python library for parsing HTML and XML documents, facilitating efficient data extraction.[5] While downloading websites is a component of the process, more sophisticated ransomware groups have incorporated Captchas into their blogs. This technology is commonly employed to distinguish between human users and bots, preventing web scrapers from accessing desired pages. Playwright enables RansomLook to bypass Captchas by directly interfacing with the browser, simulating human interactions with the website. Additionally, Playwright allows RansomLook to capture screenshots of every page reached.[6] For users of RansomLook, this approach offers a lighter weight, safer, and faster alternative to downloading every file hosted on the blog. Once data has been scraped, RansomLook stores it in Valkey, an open-source key/value database capable of storing a vast quantity of diverse data types.
On the RansomLook website, users can view quick statistics about the statistics of the site – the groups the site has tracked, the forums and markets it has tracked, and weekly, monthly, and yearly summaries of posts logged to RansomLook. Users can view posts, groups, the status of said groups’ blogs, as well as a variety of other data pertaining to the state of ransomware. There is also a “Stats” page that shows some limited visualizations pertaining to activity in the past week, month, and 90 days. These offer a decent look at the current state of ransomware but lack the full picture of the whole RansomLook database.

RansomLook Site
Alternatives
RansomLook is not the only Ransomware dashboard on the internet.[7] There are several that perform similar functions, but none as comprehensive and easily accessible as RansomLook. RansomWatch has its own GUI dashboard and is set up similarly to RansomLook, and like RansomLook is open source. However, it lacks the same depth of data that RansomLook provides. Darkfeed.io provides a more polished dashboard and includes threat intelligence and multiple useful data visualizations, which RansomLook does not. However, it does not have as much data as RansomLook. RansomLook has tracked over 16,000 attacks, while Darkfeed.io has logged just shy of 14,000. It is also not open source, which means extracting data from it to make our own analysis would be challenging and more expensive than RansomLook.

DarkFeed.io site
eCrime.ch is another dashboard alternative to RansomLook. They provide media, reports, and a newsletter surrounding ransomware attacks, which RansomLook lacks. However, like Darkfeed.io, their free tier is extremely limited and not open source, which hinders the data collection process.
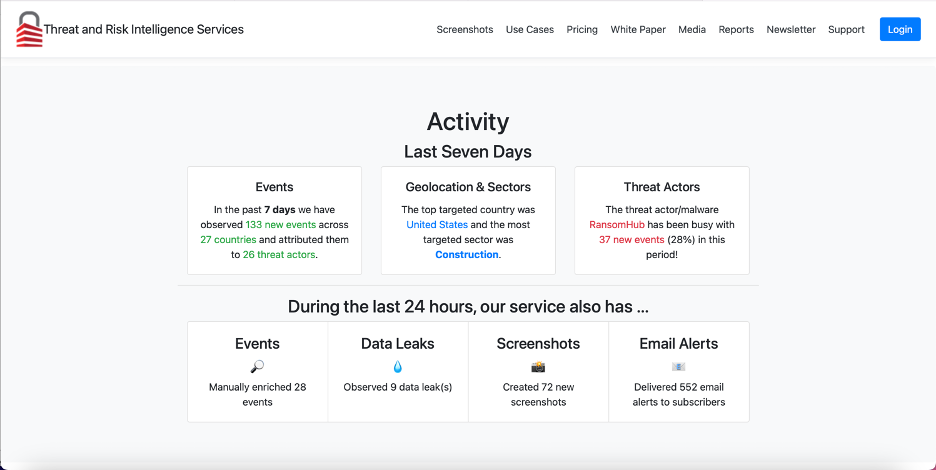
eCrime site
Use Case
Being an open-source project, RansomLook offers the ability to download all data that it hosts on its website. This enables users to not only make their own database but create visualizations that are not available on RansomLook’s site.
As part of a larger research project, we sought to create a database capable of live updating and creating dynamic visualizations. Our tech stack starts with a simple bash script. This code downloads the raw JSON data from the RansomLook repository and runs a Python preprocessing script on each JSON file to format the data for Elasticsearch – a powerful, open-source search and analytics engine designed to take large volumes of data and provide fast search capabilities. It then uses another Python script to load the data into Elasticsearch.
Once the data has been processed and fed into Elasticsearch, we can perform data analysis. Elasticsearch was chosen due to its ability to quickly parse through vast quantities of data. Our data set contains over 19,000 individual entries across several indexes, so having the ability to search for a specific property is critical. Elasticsearch also can ingest unstructured data while retaining the ability to parse through it.
Another benefit of Elasticsearch is its tight integration with Kibana, a data visualization platform. Kibana gives user the ability to create completely custom dashboards. Their library includes a plethora of pre-built visualizations and the ability to create custom visualizations.
Data visualization is at the heart of Kibana. By adding the ability to quickly create bespoke visualizations for our data, we can easier see trends in data that would be invisible if in a data table format. The integration with Elasticsearch also means that these visualizations are scalable and adapt with the data over time. Each graph, map, and data point will automatically update to fit any new data input to the database.

Elastic Dashboard
In addition to the core functionality provided by Elasticsearch and Kibana, we’ve built several custom tools to further streamline and enhance our data processing capabilities. We developed a tailored Python script that automates the extraction and transformation of specific data fields, making it easier to aggregate and analyze trends over time. Furthermore, our setup is designed with scalability in mind. As our data set continues to grow, we can seamlessly expand our infrastructure to handle increased data volume and complexity, ensuring that our visualizations remain responsive and informative. This modularity allows us to quickly adapt to new research requirements or incorporate additional data sources as needed.
Impact and Importance
RansomLook provides unparalleled insight into the murky waters of the ransomware landscape. By providing near-real-time updates on global ransomware attacks, researchers and cybersecurity professionals can gain a more nuanced understanding of this threat. The platform’s robust dataset, when paired with the power and flexibility of Elasticsearch and Kibana, allows users to generate comprehensive descriptive statistics. This capability enables users to understand global trends, geographical impacts, and detailed group statistics, offering a clearer picture of ransomware activities worldwide. As a result, RansomLook plays a critical role in developing an understanding of a significant cyber threat. The service’s data-driven approach empowers researchers to learn more about ransomware in fine detail while still being at a safe distance.
Challenges and Limitations
Despite RansomLook’s valuable contributions to ransomware research, several challenges limit its full potential. The primary limitation stems from the incomplete data collected from the ransomware blogs. Ransom actors threaten victims to post their data if they do not pay their ransom, but if they do pay, their data may never be posted. This discrepancy creates a significant blind spot in data collection. While we can estimate the reach of ransomware groups like LockBit 3.0, which has over 4,000 compromised companies on its blog, we cannot accurately measure their rates of success. The anonymous and decentralized nature of cryptocurrency transactions further complicate this issue. Payments are made using cryptocurrencies, which obscure the identity of both the payer and the payee, and while RansomLook logs certain transaction details such as the type of crypto currency, value, and transaction codes, this information is often incomplete and lacks context. The absence of data regarding the payer’s identity and the timing of the transaction adds another layer of ambiguity, hindering a comprehensive analysis of ransomware economics.
RansomLook’s strengths lie in its ability to aggregate and analyze large volumes of data, providing snapshots of ransomware activities and trends. However, to fully understand the effectiveness and ultimate success of ransomware groups, more detailed and transparent data is required, such as more insights into the ransom transactions of these groups.
Conclusion
Navigating the ransomware landscape is often like shooting an arrow in pitch black and hoping it hits a target. The structure of the Tor network, the irregular blog designs for each group, and the inherently untrustworthy nature of these criminal organizations make it difficult to get a complete understanding of the state of ransomware. RansomLook solves part of this issue. By autonomously scraping these dark web blogs and storing its metadata in a publicly available database, researchers gain insights into the state of ransomware.
By integrating RansomLook into an Elasticsearch database, researchers gain the ability to quickly parse through the large database. Pairing the database with Kibana creates new opportunities for researchers to visualize their data to better understand the effects of ransomware.
Bibliography
Kaufmann, Garrett, and Vabuk Pahari. “The Tor Architecture and Its Inherent Security Implications,” May 18, 2020. https://medium.com/@gkaufmann/the-tor-architecture-and-its-inherent-security-implications-61f45fd42b01.
Mozilla. “GeckoDriver Github.” Accessed October 4, 2024. https://github.com/psf/requests.
Nordqvist, Kim Rikard. “BACHELORARBEIT,” 2023.
PyPI. “Beautifulsoup4,” January 17, 2024. https://pypi.org/project/beautifulsoup4/.
“Requests Github.” Accessed October 4, 2024. https://github.com/psf/requests.
Robot, Scraping. “The Complete Guide To Playwright Web Scraping,” November 15, 2023. https://scrapingrobot.com/blog/playwright-web-scraping/.
Selenium. “Selenium Github.” Accessed October 4, 2024. https://github.com/SeleniumHQ/selenium.
Notes
[1] Garrett Kaufmann and Vabuk Pahari, “The Tor Architecture and Its Inherent Security Implications,” May 18, 2020, https://medium.com/@gkaufmann/the-tor-architecture-and-its-inherent-security-implications-61f45fd42b01.
[2] “Requests Github,” accessed October 4, 2024, https://github.com/psf/requests.
[3] Mozilla, “GeckoDriver Github,” accessed October 4, 2024, https://github.com/psf/requests.
[4] Selenium, “Selenium Github,” accessed October 4, 2024, https://github.com/SeleniumHQ/selenium.
[5] PyPI, “Beautifulsoup4,” January 17, 2024, https://pypi.org/project/beautifulsoup4/.
[6] Scraping Robot, “The Complete Guide To Playwright Web Scraping,” November 15, 2023, https://scrapingrobot.com/blog/playwright-web-scraping/.
[7] Kim Rikard Nordqvist, “BACHELORARBEIT” (2023).